Exploring the viability of XML for use in POPIN web sites
Technical Report to POPIN - Czech Republic
Addendum A: conversion mechanics
We present here for the first time our functional model of a conversion scheme in the sense of the creation of XML data from standard spreadsheets and their parsing into HTML documents. Several utilities can be downloaded from these www-sites and freely used. These computer programs will make it possible for you to take indispensable steps of all necessary conversions (see the picture below) as simply and flexibly as possible. We would like to stress that these are the first versions of these programs, which can be slightly modified in the future.
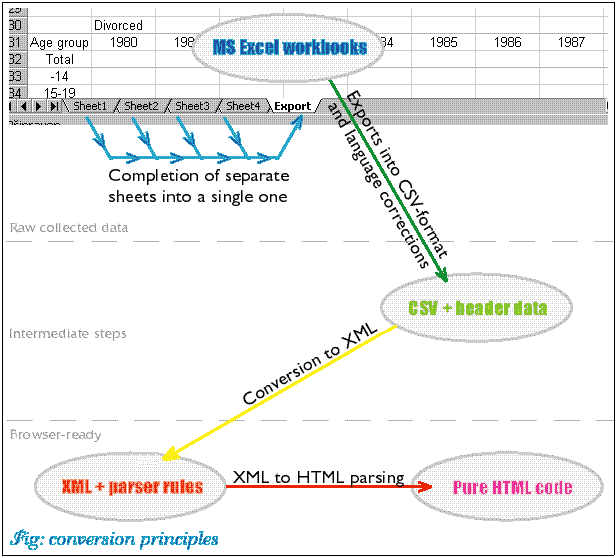
Data-sheets ordering
All data were collected into spreadsheets. Every category appeared in a separate file with several, one to thirty, worksheets. The data were typed partly manually, partly scanned from other sources. Since the data collection was preceded by a draft of tables, it was possible to develop a simple logic for future conversions:
- MS-Excel 97/2000 was used to store the data.
- All processing instructions (strings matched to have special meaning) are "case-sensitive."
- Each new table has in its first cell (such as A3 or A128) the string "Tab." and its own title in the second line of a cell (B3, B128,
.). The rest of cells on a line are ignored.
- If a table was subdivided into sub-tables, the first cell is empty and the second contains its title. The rest of cells on the line are ignored.
- The first line of a next table or a sub-table is regarded as a definition of the header of a column. Further lines are conceived as individual lines of a table, while the first cell includes the title of a line and other cells in a line contain the values stored in a relevant table. A table or a sub-table ends in the moment when the beginning of a next table or sub-table was recognized.
- The lines which in the first cell include a value ending with a colon are interpreted as separators. They have a special meaning; they can serve as an optic separator in tables that are more complex.
- No sub-table can span over more than one worksheet. The tables are ordered in the top-bottom direction within every worksheet and the left-right direction within every spreadsheet.
- Blank lines are quite ignored. As "blank" is regarded every line in which the first two cells are empty.
Producing CSV files
When developing a CSV file, destined for further conversions, one has to take several steps:
- While the workbooks are three-dimensional data structures, CSV files can only be two-dimensional. Hence, there is a need to merge all worksheets into a single sheet, which can be eventually exported as a CSV-formatted file.
- For this purpose a module was written in the Visual Basic for Applications (VBA). The module is stored in a separate workbook, whose first worksheet defines the list of files, which are to be converted, and a list of thus created, subsequent, files. The module works in a loop for each file of the list, it opens it, creates a new worksheet in it, copies into it data from all preceding worksheets and stores the new sheet into a CSV file.
- Export routines for CSV files are in the VBA broken (SaveAs function). If the MS-Office 97 is used, values are compulsorily separated with commas and a floating point is translated into a point. If a field contains a comma, the whole value is put in quotes. There is no way with which to change this behavior. However, in the Czech edition of MS-Office 2000 the VBA adopts locale settings and exports proceed along other rules. Delimiters are taken from the system. In the Czech, setting the role of separator is played by semi-colon and of decimal points by a comma. However, if the field itself includes a semi-colon, the value is not in quotes. This leads to subsequent misinterpretations of fields in a CSV file and the system is not usable. This can be resolved by changing separators in the Control panel/National settings according to the U.S. system, then the conversion module is used and eventually the original setting of the system is restored. We suppose that in the purely English-speaking environment the conversion will run without any conceptual problems, without these "manual" steps.
- As we wrote the VBA module later than other conversion programs, we decided to continue with the use of semi-colon as a separator in the subsequent work with CSV files (in the tests, in which exports were made manually, the Czech edition of the MS-Excel of all versions created data separated with semi-colons). This is why we developed a C-program, which translates the U.S. version of a CSV file into a format in which commas are replaced with semi-colons (except for text in quotes) to ensure compatibility with further programs following the previous exports.
Here you can
download
the relevant VBA module and import it into your MS-Excel workbook or at least be inspired by it when implementing your own solution.
XML factory
Now we are ready to start generating data in the XML format. In keeping with the text above, we are able to convert CSV-formatted data into a structure described by a set of XML tags. For this purpose, we had to write our own tool (a C-language program), which does this automatically with any amount of data. Now look at the list of features and advantages of the use of this tool (called "csv2xml"):
- Pure Win32-executable, linked statically. It runs fast without a need of supporting runtime-environment. It runs on MS-Windows 9x / NT / 2000 platforms, but it can be easily compiled under any operating system, supporting the ANSI-C compiler. As it operates in console (textual) mode, its source code is hardware independent.
- The program "knows" the semantic structure of data exported into the CSV format
and converts them into XML. The set of used XML tags complies with the DTD
(definition
type document, describing the syntax of allowed tags), which is part of our proposed standard and which is hard-coded into the structure of the program itself. In the future versions of this tool the names of tags and description of semantic structure of a CSV file will be defined toward the program externally, which means that all subsequent changes or more general use will be possible without the need of re-compiling the relevant program.
- All optional information is passed to a program through command line parameters. The first parameter is the name of the CSV file, which is to be processed, the second determines the name of the resulting XML file and the third is used to insert header information. Preliminary tests of data exported from the MS-Excel have led to the creation of one empty field at the end of each line of the data. This is why the first beta-version was given an extra parameter, determining whether the superfluous field should be left out in conversion, to prevent the creation of a superfluous, empty column of data in tables. Later we realized that the problem has deeper roots. The MS-Excel contains two types of cells which may appear empty: (1) never touched cells; and (2) cells whose content was deleted. The former type does not generate any data in export, but the latter does - it is printed as an empty string and it must be naturally delimited by a separator. After we realized this, we wrote a more general code, which can properly handle this situation. This is why the fourth parameter of the program is not necessary and was dropped from later versions of the program.
- As already mentioned, CSV data are combined with the "headline information," which
gives rise to an XML file, corresponding with the proposed standard. These are the data in the
<DESCRIPTION> section (look again at
our
DTD) and contain non-tabular information, jointly describing a whole set of tables and
sub-tables (the section). It has turned out that more practical is to keep this
information outside the main CSV files since it is parametric and partly optional. The model "header
set" file has revealed that each entry occupies just one line (not necessarily in the same order as in which they will appear in the XML file) and it has the following syntax: the name of a field; followed by a separator (semi-colon); followed by the value of the field. At present the names of fields and delimiting character are hard-coded in the program and cannot be changed by the user. But since this is the same information as that used in the DTD, this information, too, will be configurable in the future, except for a few tags such as the DTD_NAME, which deal more with the function of the program rather than the structure and content of the converted data.
Nevertheless, the program does not yet support everything we would like to have included in it. Despite this, it is able to do whatever needed in conversions. This is the list of limitations of the tool "csv2xml":
- If a tag does not contain any data, it is not reproduced in the "shortened mode" (such as should be instead of ). This is to be redressed in the process of further development of the program. By the way, the MS Internet Explorer is able to correctly translate empty tags.
- The program contains some limits concerning the length of strings - each element of the type #PCDATA can have a length of up to 10,240 characters. Each line of a CSV file can have a length of up to 102,400 characters and can contain a maximum of 256 fields (cells). At least the number of fields in a line is not to be so strictly limited in future versions (dynamically allocated).
If you are interested in this tool, you can download and use it to perform the conversions of your data.
Producing HTML code
The next step involves the graphical interpretation of data, especially for those who do not need or who is unable to get data in the XML format. Until now, only one of the two most used browsers supports a direct understanding of XML. Moreover, there is still no efficient method for combining XML tags with its graphic layout (CSS does not support tables and XSL is a proprietary solution of a single manufacturer). Therefore, we have decided to give the user two alternatives of getting the data: (1) pure XML for easy data transfer between various applications (especially in the near future); and (2) the same data presented in the graphical form (a table) as part of this www-project. In order to work with a single instance of collected data (not only with a differently formatted copy of the original data set), we developed a tool, which parses XML data into the form of an HTML document on-line (dynamically) upon request of the user. This tool can also be used for static conversions, although it was developed especially for dynamic work. It can operate as an extension of the web-server (CGI script) in real time. The layout of the data is generated on the server side and is then interpreted by any browser as HTML page. This means that the data are available regardless of the browser's ability to read and interpret the XML code and to create a relevant layout for it.
Now let's look at the list of features of this tool ("xmlparse"). If you find it useful for the presentation of your own data, you can download it here (Win32-clone).
- Since this program is written in the ANSI-C, it is easily portable to most platforms. We have tested it under the following operating systems: Windows 95/NT, Tru64 Unix (DEC Unix, Digital Unix, OSF/1), RedHat Linux.
- Depending on the number of parameters with which it was started, it automatically distinguishes its mode of work - if there is one parameter, it runs in the CGI mode (such as http://www.site.com/cgi-bin/xmlparse?rules=/rules/tables01.par&data=/xml/mortality.xml); if there are two parameters, it operates in the command-line mode (i.e. xmlparse mortality.xml tables01.par > mortality.html).
If it runs as CGI, methods GET and POST are distinguished according to the content of the QUERY_STRING environment variable value. It requires two values, named "rules" for the filename containing the list of rules for the generation of the layout (parsing rules), and "data" with the name of the file, which includes the data themselves. In the command-line mode, the parameter "data" must be given as the first and the "rules" as the second. In both operational modes, the output is generated on a standard output channel, which can be redirected to the www-browser or a file.
- The parse-rules are defined in the following way: every rule is described with one line in the file containing rules. Each line contains the XML tag to be replaced and the relevant replacing HTML structure. They are separated by a comma without useless spaces. If nothing follows the comma, it means that the relevant XML tag is to be excluded.
- This tool can also be used to generally replace one set of strings in text with another set of strings.
- As the rules of replacing the tag are stored in an independent text file, its editing can immediately influence the layout of generated documents without the need of recompiling the whole program.
- Moreover, it is also possible to change the parse rules during the conversion flow. When the program meets in the data the string <!-RULE=filename-->, it downloads the rules from the file in question and from this place replaces with them previous rules, loaded when the program started. This change can be repeated as often as needed.
Despite this, this tool, too, has some limitations. This program does not support all possible features offered by the XML specification. However, it is still able to make whatever needed in conversions. Here is a list of limitations of the tool "xmlparse":
- Only external DTD of category "system" are allowed, neither "public" nor "inline" DTDs are supported. You can simply change the DTD mode after generating a document in XML format by manual editing. Support is only provided to one DTD level (no recurrent included).
- Parametric entities are not supported. Static entities used for the replacement of text are allowed and properly processed. If there is recurrent replacement, it is not allowed to use self-containing entities. Further versions of the program are to include the possibility of turning off recurrent replacement of text.
- There are certain limitations concerning the length of processed strings - each line of an XML file can have the maximum length of 10,240 characters.
<< CONTENT | ADDENDUM B: DOWNLOADS >>
|

